
현재 수강중인 학교 수업에서 곧 다루긴 하겠지만,
Spark에 대해 먼저 알아보고 싶어서 유투브 강의 영상을 보며 공부해보자.
(Spark Tutorial이라고 검색해서 조회수 + 최근 업로드 영상 기준으로 선택했다. )
개인 공부 내용이며, 영어로만 재생되기 때문에 내용이 확실하진 않다.
(틀린 내용이 있으면 코멘트 부탁드립니다.)
www.youtube.com/watch?v=zC9cnh8rJd0
Intro
- Spark은 분산 데이터 처리 엔진이다.
- Spark는 다양한 기능이 unified되어 있다.

기존 Hadoop 위에서 돌아가던 ML library, Mahout이나 real-time streaming data를 처리하기 위한 Storm 등, 다양한 툴에 대해, 2014년에 나온 Spark는 위의 다양한(50+) 기능을 자체적으로 처리 가능하다.
- Spark는 in memory 방식이다.
- MapReduce는 모든 Iteration에서 HDD I/O.
- Spark는 더 쉽다.(MapReduce에 비해)
- 하나의 언어로 Hadoop MapReduce위에서 실행되던 기능들을 모두 다룰 수 있다.
- Spark는 Storage가 없다. → Spark is an execution engin!(MapReduce 처럼. 이 점이 Spark와 MapReduce를 같은 선상에 두는 이유이다.)
- 하지만 거의 모든 File System(ex. HDFS) 또는 Object Storage(S3)와 연동할 수 있다.
- 다양한 NoSQL DB, RDBMS에서도 데이터를 가져올 수 있다.
- 실시간 데이터를 처리하는 Kafka, Flume 등과 연동할 수 있다.(데이터 처리에 대한 신뢰성 보장)
- (실시간 데이터를 바로 Spark로 가져오게 하면 만약 특정 receiver 머신이 down되었을 때 데이터 손실이 발생한다. 물론 down이 확인되면 다른 머신을 receiver로 지정하겠지만 변경되는 시간 동안 수 많은 데이터가 손실 될 것이다.)
- Spark 의 cluster mode managing은 대표적으로 Standalone, MESOS, YARN이 있다. (추후 알아보자)
- 위 모든 modes들은 Hadoop ecosystem의 ZooKeeper로 효율적으로 관리된다. (추후 알아보자)
- ex. 어떤 노드가 무슨 일을 하는지, 어떤 노드가 Active 상태인지, etc. 모두 ZooKeeper에게 물어본다.
- 위 모든 modes들은 Hadoop ecosystem의 ZooKeeper로 효율적으로 관리된다. (추후 알아보자)

Spark VS Hadoop
처리 과정
- Hadoop MapReduce는 모든 처리 단위마다 HDFS → MapReduce → HDFS 과정을 거친다. HDFS는 HDD에 데이터를 나누어 저장하는 분산 파일 시스템이기 때문에 결국 매 단계마다 HDD I/O가 발생한다.
- Spark는 필요한 데이터를 HDFS로 부터 한 번에 불러와 RAM에 저장하고 이후에는 RAM으로 부터 읽고 쓰는 In Memory 연산을 하고, 최종적인 output에 대해서만 다시 HDD에 저장한다. (10~100 times faster than MapReduce)
- 절대적으로 RAM만 사용해야 하는건 아니다.
분산 처리 시스템은 Driver와 executor가 있고, Master - Slave 관계로 볼 수 있다.
Spark 또한 이런 concept를 가지고 있다.
Local Mode
- 하나의 JVM(Container)에서 Driver와 Executor가 실행된다.
- 비효율적
- testing purpose
Cluster Mode
- Driver와 여러개의 Executor(ex. in DataNode)가 실행된다. 각각 Container로 구성되어 있다.
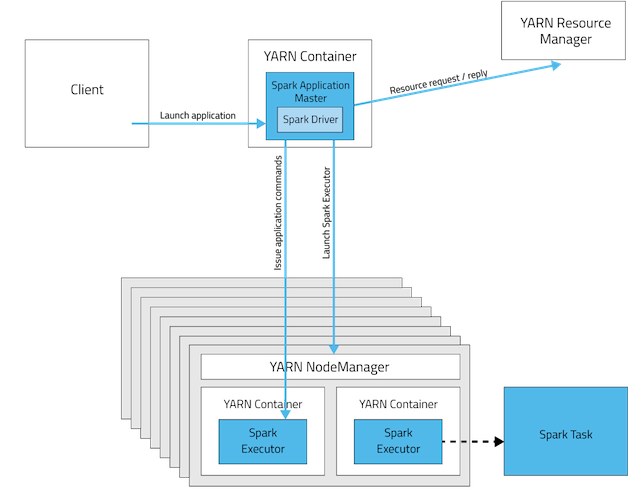
- 분산 처리를 하지만 고려할 점이 많다.
- 얼마나 많은 memory가 필요한지, 몇개의 executor를 사용할지, etc.
- Spark의 full performance를 위해.
- Hadoop Cluster에서는 Yarn을 통해 조정한다.
- 얼마나 많은 memory가 필요한지, 몇개의 executor를 사용할지, etc.
- 이후 Spark processing을 위한 프로그램을 실행하면, Yarn이 전체 Cluster를 실행하고, Driver 머신이 Executor 들에게 테스크 실행 명령, 실행 결과물은 일반적으로 다시 Driver에게 전달되고, 사용자가 지정한 storage로 적재한다.
'IT study > Big Data' 카테고리의 다른 글
| [YouTube]Apache Spark Tutorial Full Course - Job, Stage, Task (3) (0) | 2021.05.12 |
|---|---|
| [YouTube]Apache Spark Tutorial Full Course - RDD (2) (0) | 2021.05.10 |
| Hadoop MapReduce( + Yarn) (0) | 2021.04.27 |
| Data Analysis(Python) (0) | 2021.04.16 |
| HDFS(feat. S3) (0) | 2021.04.09 |