
반응형
대용량 데이터 저장과 관련된 포스팅을 하면서HDFS에 대해 알아봤었는데, HDFS는 데이터 분산 처리 오픈소스 프레임워크 Hadoop에서 데이터 저장을 위한(=분산 저장을 위한) file system이라고 했었다.
이어서,
MapReduce
- MapReduce는 Hadoop이 제공하는 전체 분산처리 시스템 안에서
실질적으로 '데이터 처리'를 담당하는 소프트웨어 프레임워크라고 할 수 있다.
(현재는 MapReduce가 가지고 있던 자원 관리 역할은 Yarn이 담당하고 있다. 따라서 MapReduce의 동작 방식도 달라졌다. 우선 기존의 MapReduce 방식을 이해하고, 이후에 Yarn이 나오면서 변경된 점 위주로 학습해보자.)
- MapReduce는 데이터 처리 동작 전체를 관할하는 하나의 JobTracker와 실질적으로 데이터 처리가 실행되는 여러개의 TaskTracker로 작동된다. (HDFS의 NameNode, DataNode처럼 Master - Slaves 구조이다.)
- MapReduce의 동작은 HDFS위에서 일어나지만 동작 자체가 HDFS에 저장된 데이터들에 영향을 주는 것은 아니라고 한다.
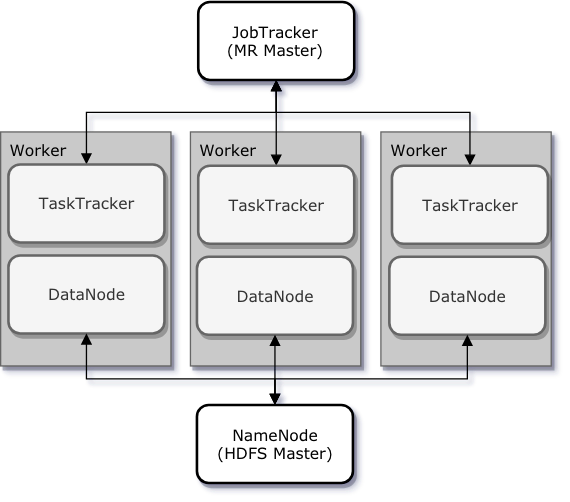
- JobTracker : hadoop에 있는 모든 Job을 스케줄링/모니터링 하는 소프트웨어.
- Job : client가 수행하려는 작업(Input data, MapReduce program, etc)
- 입력 데이터를 몇개의 split으로 나눌지 결정, HDFS에 분산 저장.
- map과 reduce를 위한 TaskTracker들 결정(= map, reduce를 위한 WorkerNode들 결정)
- 처리 과정 모니터링
- 각 TaskTracker들의 상태(heartbeat), 처리 현황(DataNode의 block report처럼..)을 주기적으로 전달 받는다.
- 특정 TaskTracker에 오류가 발생하면 다른 TaskTracker에서 Task를 처리하도록 해준다.
- TaskTracker : DataNode에 위치하여, task를 처리하도록 해주는 소프트웨어.
- mapper Node는 자신에게 주어진 데이터를 local로 가져와 map 함수 실행
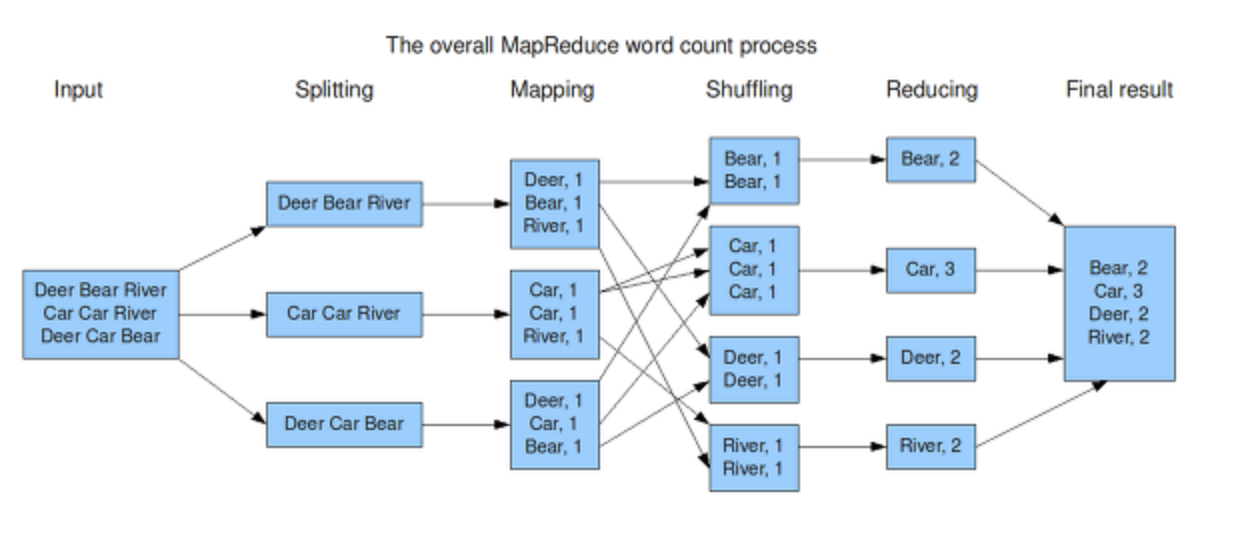
- mapping : 데이터를 파싱하여 key-value 형태로 바꿔준다.
- mapping 이후 reducing 전에 suffling이라는 과정이 있다. mapping 결과로 key-value 형태의 데이터 더미를 각reduce task에게 적합한 형태로 전달해주기 위한 처리 과정이다.( 참고한 포스트마다 suffling의 포괄 범주가 다르다.. 아무튼 아래의 과정들은 mapping 이후 reducer에게 전달되기 전까지의 과정들이다.)
- combining : key-value 더미들을 key-{value1, value2, ...} 처럼 리스트화 해준다. 이 과정으로 reducing 처리의 부하가 줄어드는 효과가 있다.
- partitioning : key들을 전달해줘야 할 reducer 기준으로 분리해준다.
- reducer Node는 mapperNode로 부터 mapping(from mapper)된 데이터를 가져와 reduce 함수 실행
- mapper Node로부터 데이터를 가져온 뒤, 우선 sorting을 해준다.
- key1-{....}, key2-{....}, key1-{....}, key2-{....} 를 key1-{....},key1-{......}, key2-{....},key2-{....} 처럼 특정 key에 대한 value list들을 정렬해주는 것이다. 이 또한 suffling과정과 같은 효과이다.
- reducing : 사용자가 원하는 정보를 최종 산출하는 단계이다.
- mapper Node로부터 데이터를 가져온 뒤, 우선 sorting을 해준다.
- 주기적으로 JobTracker에게 상태, 진행 현황 보고
- mapper Node는 자신에게 주어진 데이터를 local로 가져와 map 함수 실행
출처 :
dabingk.tistory.com/8(yarn)
blog.geunho.dev/posts/hadoop-yarn/
stackoverflow.com/questions/27497734/datanode-and-tasktracker-on-separate-machines
반응형
'IT study > Big Data' 카테고리의 다른 글
| [YouTube]Apache Spark Tutorial Full Course - Job, Stage, Task (3) (0) | 2021.05.12 |
|---|---|
| [YouTube]Apache Spark Tutorial Full Course - RDD (2) (0) | 2021.05.10 |
| [YouTube]Apache Spark Tutorial Full Course - Intro, spark, cluster (1) (0) | 2021.05.01 |
| Data Analysis(Python) (0) | 2021.04.16 |
| HDFS(feat. S3) (0) | 2021.04.09 |